Textdatenbank und Wörterbuch des Klassischen Maya
Überblick
Zielsetzung und Projektarchitektur

Die digitale Erforschung der Mayaschrift: Wege und Grenzen digitaler Inschriftenforschung
Bild © Berliner Antike-Kolleg / YouTube
Präsentation und Archivierung der Forschungsdaten
Das virtuelle Inschriftenarchiv mit Abbildungen, Transkriptionen und Übersetzungen wird langfristig in den Digitalen Sammlungen der ULB integriert und steht für die Öffentlichkeit zur freien Recherche zur Verfügung (siehe Abbildung unten). Für die Erstellung, Verwaltung und Speicherung der textuellen und graphischen Korpusdaten wird die Virtuelle Forschungsumgebung TextGrid (SUB) eingesetzt, die ein vernetztes, kollaboratives Arbeiten ermöglicht und eine Arbeitsplattform für sprachwissenschaftliche und korpuslinguistische Informationstechnologien bietet.
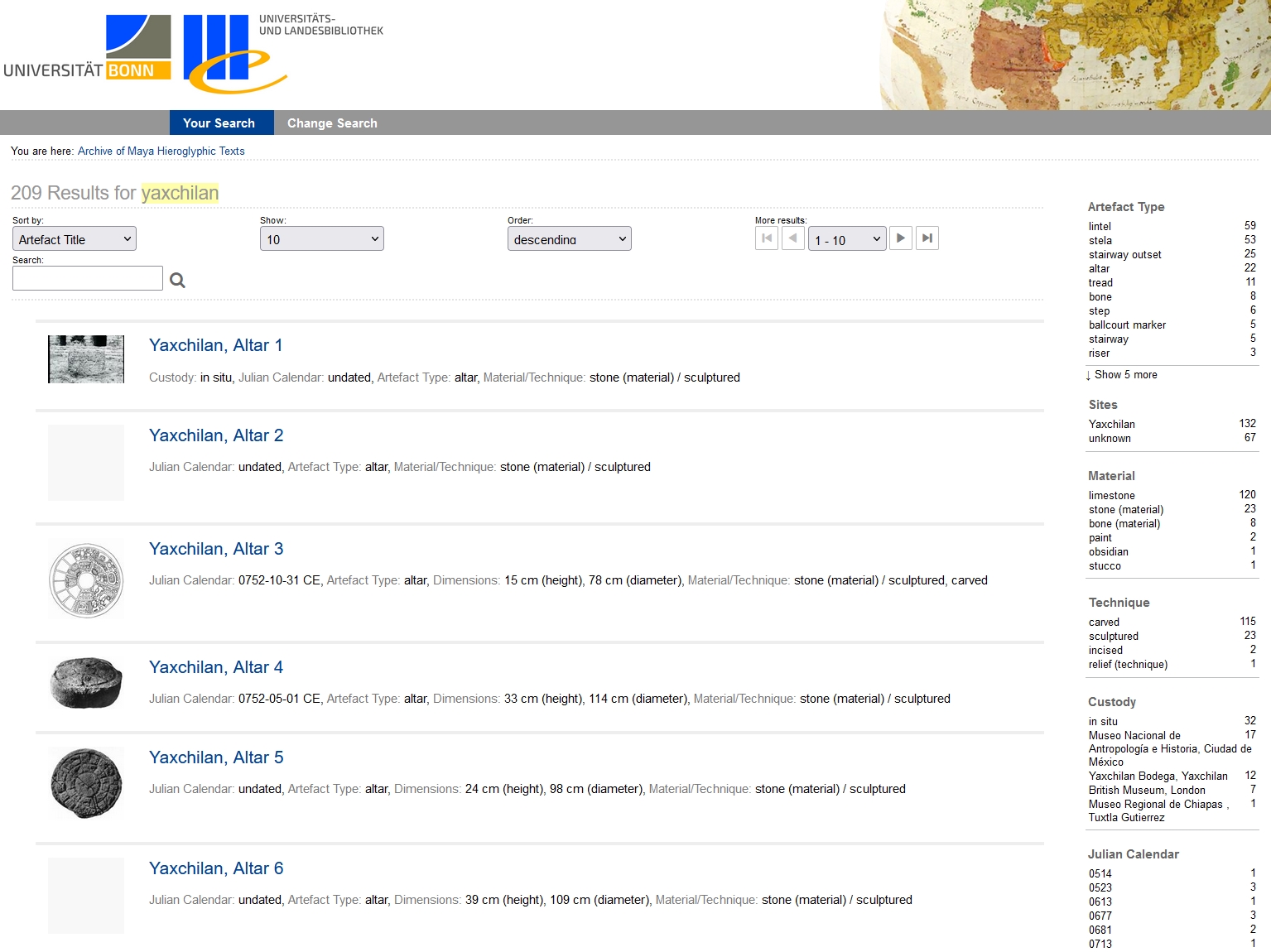
Die lexikalische Datenbank wird als Bestandteil der Virtuellen Forschungsumgebung TextGrid eingebunden und archiviert, so dass die Forschungsdaten über den Ablauf des Projekts hinaus langfristig aufbewahrt werden. Das gedruckte Wörterbuch wird gegen Ende der Projektlaufzeit ediert und veröffentlicht. Zuvor werden regelmäßig um neue oder aktualisierte Daten ergänze Vorversionen publiziert, so dass alle Forschungsdaten im Laufe des Projekts vollumfänglich Open Access für die Öffentlichkeit zugänglich sind.
Projektleitung:
Prof. Dr. Nikolai Grube
Forschungsteam:
Dr. Christian Prager (Epigraphik & Projektkoordination)
Elisabeth Wagner M.A. (Epigraphik & Ikonologie)
Antje Grothe M.A (Metadaten und Bibliographie)
Guido Krempel M.A. (Epigraphik)
Tobias Mercer BA (Informatik)
Börge Kiss, MALIS (Informatik, CCeH)
Maxim Ionov (Informatik, CCeH)
Kooperationen mit Institutionen und Wissenschaftlern im In- und Ausland
Staats- und Universitätsbibliothek Göttingen
Cologne Center for eHumanities
Laufzeit: Seit 2014 - 2028
Förderung: Nordrhein-Westfälische Akademie der Wissenschaften und Künste, Union der Wissenschaftsakademien
Kooperation: Aufbau und Pflege der computerbasierten Infrastruktur sowie die Präsentation der digitalen Forschungsdaten basieren auf Kooperationen zwischen dem Projekt und der Universitäts- und Landesbibliothek Bonn (ULB), der Staats- und Universitätsbibliothek Göttingen (SUB) sowie dem Cologne Center for eHumanities.